library(starwarsdb)
library(tidyverse)
library(nycflights13)8 Datenzusammenführung
Nur selten beziehen wir alle Daten, die wir auswerten oder visualisieren möchten, an einem einzigen Ort bzw. in einer einzigen Datei. Um dies zu bewerkstelligen, müssen wir begreifen, wie Tabellen miteinander zusammenhängen und welche Funktionen wir nutzen können, um sie zusammenzuführen.1
In diesem Kapitel lernen wir…
- …was Datenzusammenführung in Form sog. joins bedeutet.
- …welche unterschiedlichen Arten von joins es gibt.
- …wie wir im Rahmen des
tidyverseunterschiedliche Arten von joins ausführen.
Wir benötigen hierfür die folgenden Pakete:
8.1 Was sind Joins?
Im Data Science-Jargon wird das Zusammenführen von Daten in Tabellenform als joining (zu deutsch “zusammenführen”, “verbinden”) bezeichnet, der einzelne Schritt als join. Dabei werden zwei grundsätzliche Arten von joins unterschieden:
- Mutating joins: Bei diesen joins werden einer Tabelle auf Basis von passenden Beobachtungen in einer anderen Tabelle neue Variablen hinzugefügt.
- Filtering joins: Bei diesen joins werden Beobachtungen in einer Tabelle auf Basis von (nicht-)passenden Beobachtungen in einer anderen Tabelle gefiltert.
Grundsätzlich lautet die zu klärende Frage beim Zusammenführen von Tabellen also immer: Gibt es eine Übereinstimmung? Oder, um die zentrale Frage der digitalen Praxis der Partnervermittlung zu bemühen: Is it a match?

8.2 Schlüsselfelder
8.2.1 Definition
Joins hängen davon ab, dass zwei miteinander zusammenzuführende Tabellen sog. Schlüsselfelder (keys) enthalten. Ein sog. Primärschlüssel (primary key) ist eine Variable, die jede Beobachtung in einer Tabelle eindeutig identifiziert. Werden mehrere Variablen benötigt, um eine Beobachtung eindeutig zu identifizieren, ist von zusammengesetzten Schlüsseln (compound keys) die Rede. Wo der bzw. die Schlüssel auch in einer zweiten Tabelle vorhanden sind, sprechen wir vom Fremdschlüssel (foreign key).
Anschauliche Beispiele bieten die unterschieden data frames aus dem uns bereits bekannten Package nycflights13 (Kapitel 4.5):
airlinesenthält zwei Variablen: die Abkürzung jeder Fluggesellschaft sowie ihren vollen Namen. Als kürzerer und einfacherer Primärschlüssel bietet sich alsocarrieran.
airlines# A tibble: 16 × 2
carrier name
<chr> <chr>
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
6 EV ExpressJet Airlines Inc.
7 F9 Frontier Airlines Inc.
8 FL AirTran Airways Corporation
9 HA Hawaiian Airlines Inc.
10 MQ Envoy Air
11 OO SkyWest Airlines Inc.
12 UA United Air Lines Inc.
13 US US Airways Inc.
14 VX Virgin America
15 WN Southwest Airlines Co.
16 YV Mesa Airlines Inc. airportsenthält acht Variablen: einen dreistelligen internationalen Code sowie den Namen und unterschiedliche geographische und zeitliche Informationen. Als Primärschlüssel bietet sich auch hier der Code (faa) an.
airports# A tibble: 1,458 × 8
faa name lat lon alt tz dst tzone
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/…
2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A America/…
3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/…
4 06N Randall Airport 41.4 -74.4 523 -5 A America/…
5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A America/…
6 0A9 Elizabethton Municipal Airport 36.4 -82.2 1593 -5 A America/…
7 0G6 Williams County Airport 41.5 -84.5 730 -5 A America/…
8 0G7 Finger Lakes Regional Airport 42.9 -76.8 492 -5 A America/…
9 0P2 Shoestring Aviation Airfield 39.8 -76.6 1000 -5 U America/…
10 0S9 Jefferson County Intl 48.1 -123. 108 -8 A America/…
# ℹ 1,448 more rowsplanesenthält neun Variablen: einen für jedes Flugzeug individuellen Code sowie unterschiedliche technische Informationen. Abermals ist der Code (tailnum) als Primärschlüssel besonders geeignet.
planes# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,312 more rowsweatherenthält 15 Variablen: einen Code für jeden Flughafen sowie Wetterangaben für unterschiedliche Tage und Uhrzeiten; in der Variablentime_hoursind Tages- und Uhrzeit zusammengefügt. Als zusammengesetzter Schlüssel böte sich hier also eine Kombination ausoriginundtime_houran.
8.2.2 Schlüsselfelder überprüfen
Bislang haben wir nur behauptet, dass bestimmte Variablen geeignete Primär- oder zusammengesetzte Schlüssel sind. Wir können überprüfen, ob dies wirklich so ist, indem wir mithilfe von count() (Kapitel 4.3.1) die Häufigkeit von einem oder mehreren Schlüsselfeldern zählen und sichergehen, dass keine Kombination häufiger als einmal vorkommt. Möchten wir also wissen, dass carrier ein geeigneter Schlüssel von airlines ist, gehen wir so vor:
airlines |>
count(carrier) |>
filter(n > 1)# A tibble: 0 × 2
# ℹ 2 variables: carrier <chr>, n <int>Unsere Ergebnistabelle hat null Zeilen, es kommt also kein carrier-Wert mehr als einmal vor. Die Variable ist als Schlüsselfeld geeignet. Wie steht es mit origin in weather?
weather |>
count(origin) |> # Anzahl vorhandener Werte zählen
filter(n > 1) # Nur Werte angeben, die häufiger als einmal vorhanden sind# A tibble: 3 × 2
origin n
<chr> <int>
1 EWR 8703
2 JFK 8706
3 LGA 8706Alle drei Flughäfen kommen mehr als 8700 Mal vor, origin allein ist also kein geeigneter Schlüssel. Was aber, wenn wir time_hour hinzunehmen?
weather |>
count(origin, time_hour) |>
filter(n > 1)# A tibble: 0 × 3
# ℹ 3 variables: origin <chr>, time_hour <dttm>, n <int>Das sieht viel besser aus. Gemeinsam kommen origin und time_hour jeweils nur einmal vor, es gibt also für jeden Flughafen an jedem Tag zu jeder Stunde nur eine Beobachtung.
8.2.3 Primär- und Fremdschlüssel
Sobald wir passende Schlüssel in einer Tabelle identifiziert haben, stellt sich die Frage, welche Variablen als Primärschlüssel in einer Tabelle auch in einer anderen Tabelle als Fremdschlüssel vorhanden sind. Bei näherer Betrachtung von airlines, airports, weather und (der uns bereits bekannten Tabelle) flights können wir folgende Verbindungen erkennen:
flights$tailnumentsprichtplanes$tailnum.flights$carrierentsprichtairlines$carrier.flights$originentsprichtairports$faa.flights$destentspricht ebenfallsairports$faa.flights$originin Verbindung mitflights$time_hourentsprichtweather$originin Verbindung mitweather$time_hour.
Visuell können wir die Verbindungen zwischen den Primärschlüsseln in airlines, airports, planes sowie weather und den Fremdschlüsseln in flights mit verbindenden Pfeilen darstellen.
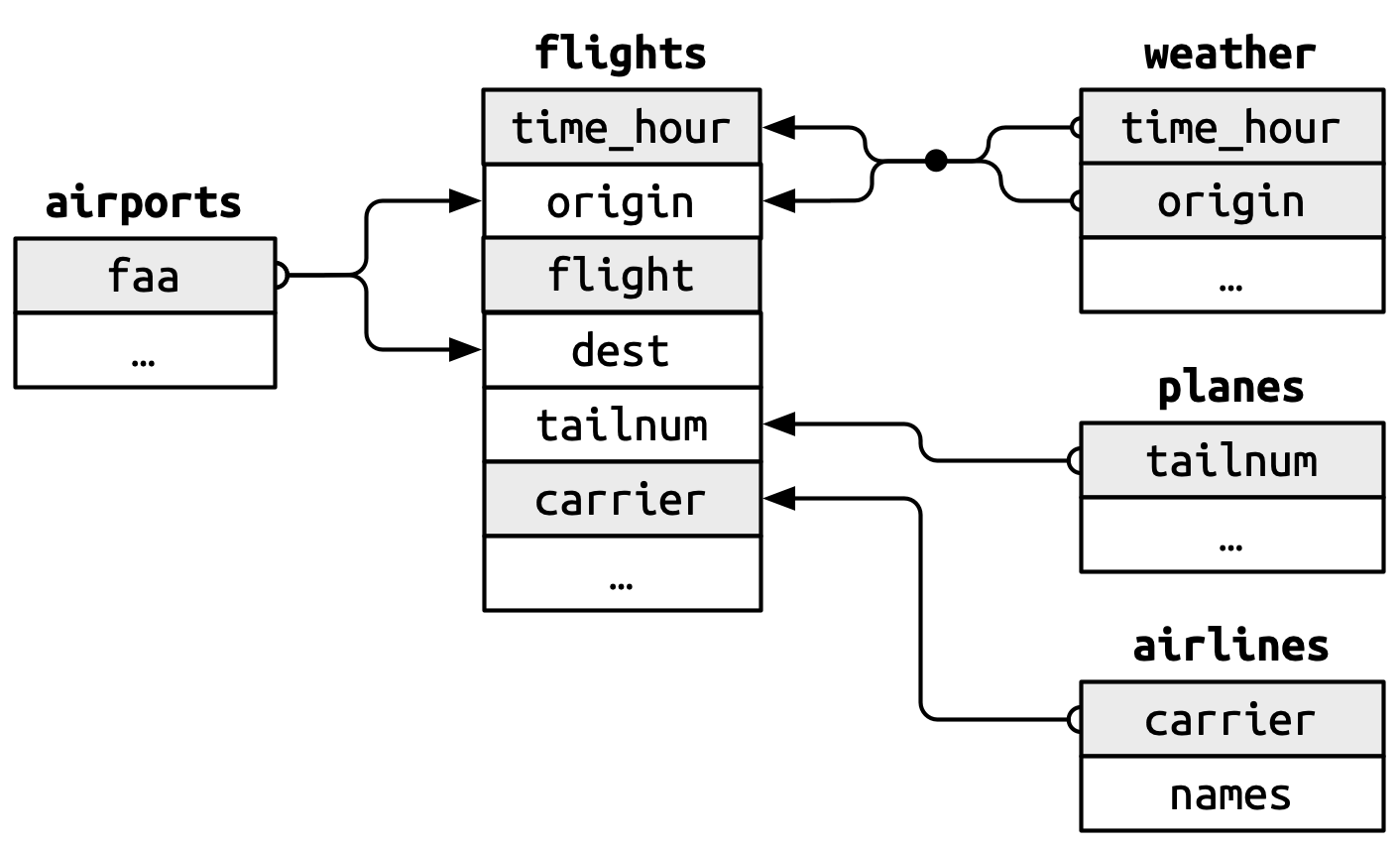
airlines, airports, planes, weather und Fremdschlüsseln in flights (Wickham, Çetinkaya-Rundel, und Grolemund 2023, Kap. 19.2).Dabei ist wichtig, festzuhalten, dass in diesen Beispielen alle Schlüsselfelder identische Namen tragen. Das ist ein vereinfachender Umstand, der leider nicht immer vorliegt.
8.3 Arten von Joins
8.3.1 Mutating Joins
Durch das tidyverse-Paket dplyr (Kapitel 4.1.1) stehen uns insgesamt sechs *_join()-Funktionen zur Verfügung: left_join(), right_join(), full_join(), inner_join(), semi_join() und anti_join().2 All diese Funktionen benötigen zwei data frames (x und y). Das Ergebnis eines joins ist immer ein weiterer data frame, wobei die Reihenfolge der Zeilen durch x bestimmt wird.
8.3.1.1 Left Join
Die vermutlich am häufigsten genutzte Spielart eines joins ist ein left join. Bei einem solchen mutating join werden auf Grundlage eines Schlüsselfeldes alle Zeilen von x durch passende Variablen von y ergänzt. Die Angabe left bezieht sich darauf, dass es die “linke” Tabelle ist, die bestimmt, wie die zusammengeführte Tabelle aussieht. Die Ergebnistabelle enthält alle Zeilen aus x und fügt dort, wo sich eine Verbindung durch das Schlüsselfeld ergibt, alle Spalten aus y ein.
Visuell können wir uns den Ablauf eines left_join() wie folgt vorstellen:
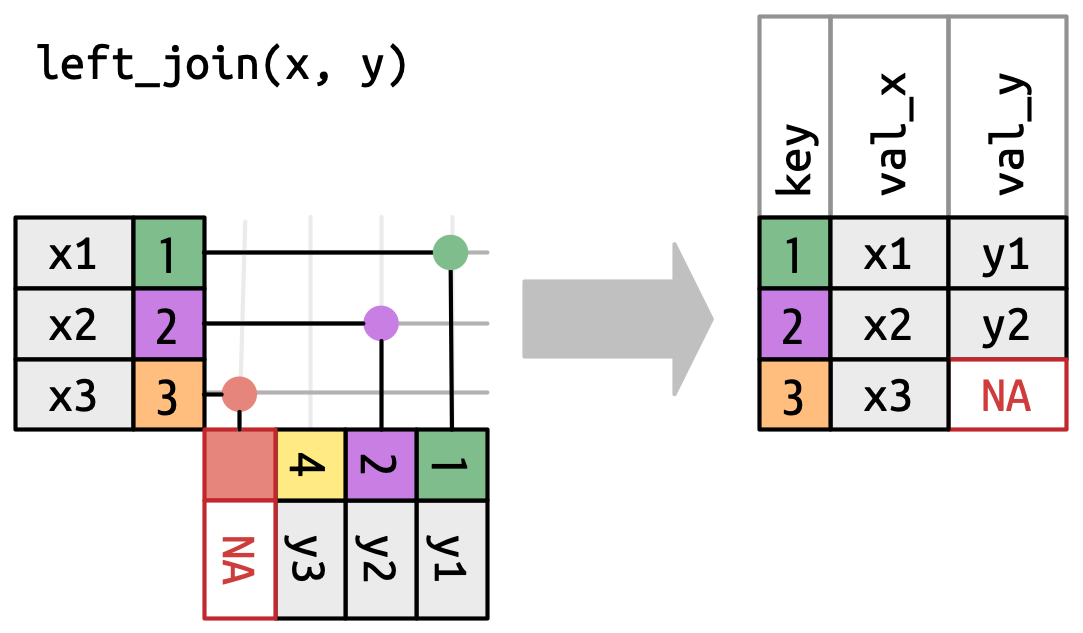
left_join() (Wickham, Çetinkaya-Rundel, und Grolemund 2023, Kap. 19.4).Nehmen wir als Beispiel an, wir würden die ausgeschriebenen Namen der Fluggesellschaften aus airlines unserer Tabelle flights2 (einer Auswahl von flights) hinzufügen wollen:
flights2 <- flights |>
select(time_hour, flight, origin, dest, carrier, tailnum) # Auswahl an Variablen treffen und einem Objekt namens flights2 zuschreiben
flights2# A tibble: 336,776 × 6
time_hour flight origin dest carrier tailnum
<dttm> <int> <chr> <chr> <chr> <chr>
1 2013-01-01 05:00:00 1545 EWR IAH UA N14228
2 2013-01-01 05:00:00 1714 LGA IAH UA N24211
3 2013-01-01 05:00:00 1141 JFK MIA AA N619AA
4 2013-01-01 05:00:00 725 JFK BQN B6 N804JB
5 2013-01-01 06:00:00 461 LGA ATL DL N668DN
6 2013-01-01 05:00:00 1696 EWR ORD UA N39463
7 2013-01-01 06:00:00 507 EWR FLL B6 N516JB
8 2013-01-01 06:00:00 5708 LGA IAD EV N829AS
9 2013-01-01 06:00:00 79 JFK MCO B6 N593JB
10 2013-01-01 06:00:00 301 LGA ORD AA N3ALAA
# ℹ 336,766 more rowsUm dies zu tun, verbinden wir flights2 durch |> mit left_join(). Weil flights2 bereits als erster Parameter (also x) in left_join() eingeht, nimmt airlines die Rolle von y ein.
flights2 |>
left_join(airlines) # Left join durchführen# A tibble: 336,776 × 7
time_hour flight origin dest carrier tailnum name
<dttm> <int> <chr> <chr> <chr> <chr> <chr>
1 2013-01-01 05:00:00 1545 EWR IAH UA N14228 United Air Lines Inc.
2 2013-01-01 05:00:00 1714 LGA IAH UA N24211 United Air Lines Inc.
3 2013-01-01 05:00:00 1141 JFK MIA AA N619AA American Airlines In…
4 2013-01-01 05:00:00 725 JFK BQN B6 N804JB JetBlue Airways
5 2013-01-01 06:00:00 461 LGA ATL DL N668DN Delta Air Lines Inc.
6 2013-01-01 05:00:00 1696 EWR ORD UA N39463 United Air Lines Inc.
7 2013-01-01 06:00:00 507 EWR FLL B6 N516JB JetBlue Airways
8 2013-01-01 06:00:00 5708 LGA IAD EV N829AS ExpressJet Airlines …
9 2013-01-01 06:00:00 79 JFK MCO B6 N593JB JetBlue Airways
10 2013-01-01 06:00:00 301 LGA ORD AA N3ALAA American Airlines In…
# ℹ 336,766 more rowsDas Ergebnis unseres joins sieht fast so aus wie flights2, aber nur fast. Tatsächlich wurde für jede Zeile aus flights2 auf Basis des Schlüsselfeldes carrier (wie aus der Meldung abzulesen ist) ein passender Wert aus der Spalte name, die sich in airlines findet, eingefügt. Unsere Ursprungstabelle hat also eine zusätzliche Spalte dazugewonnen. Die beiden Tabellen wurden erfolgreich zusammengeführt.
Explizite Angabe der Schlüsselfelder
Im bisherigen Beispiel left_join(flights2, airlines) hat R das geeignete Schlüsselfeld (carrier) selbst erkannt. Was aber, wenn R einmal nicht die richtigen Felder erkennt? Oder wenn die Schlüsselfelder zwar vorhanden sind, aber nicht dieselbe Bezeichnung tragen? In diesem Fall nutzen wir den Parameter by, um mit einem Vektor Schlüsselfelder explizit anzugeben3. Um das obige Ergebnis mit eigenen Einstellungen zu erzielen, würden wir unseren Code wie folgt ergänzen:
flights2 |>
left_join(airlines,
by = "carrier") # Gleichnamiges Schlüsselfeld angeben# A tibble: 336,776 × 7
time_hour flight origin dest carrier tailnum name
<dttm> <int> <chr> <chr> <chr> <chr> <chr>
1 2013-01-01 05:00:00 1545 EWR IAH UA N14228 United Air Lines Inc.
2 2013-01-01 05:00:00 1714 LGA IAH UA N24211 United Air Lines Inc.
3 2013-01-01 05:00:00 1141 JFK MIA AA N619AA American Airlines In…
4 2013-01-01 05:00:00 725 JFK BQN B6 N804JB JetBlue Airways
5 2013-01-01 06:00:00 461 LGA ATL DL N668DN Delta Air Lines Inc.
6 2013-01-01 05:00:00 1696 EWR ORD UA N39463 United Air Lines Inc.
7 2013-01-01 06:00:00 507 EWR FLL B6 N516JB JetBlue Airways
8 2013-01-01 06:00:00 5708 LGA IAD EV N829AS ExpressJet Airlines …
9 2013-01-01 06:00:00 79 JFK MCO B6 N593JB JetBlue Airways
10 2013-01-01 06:00:00 301 LGA ORD AA N3ALAA American Airlines In…
# ℹ 336,766 more rowsWenn das Schlüsselfeld in x oder y einen anderen Namen hätte, würden wir diese Felder mithilfe von by “gleichsetzen”. In diesem Beispiel heißt das Schlüsselfeld in airlines CARRIER. Wenn wir einen left join ohne Nutzung von by probieren, erhalten wir eine Fehlermeldung.
flights2 |>
left_join(airlines |>
rename(CARRIER = carrier)) # Variable umbenennenR warnt uns, weil es keinen gemeinsamen Schlüssel finden kann: Error in left_join(): ! by must be supplied when x and y have no common variables. Um diesen Fehler zu korrigieren, geben wir mit by = c("carrier" = "CARRIER") an, dass das Schlüsselfeld in den Tabellen jeweils anders benannt ist. Dann glückt der join ohne Probleme.
flights2 |>
left_join(airlines |>
rename(CARRIER = carrier),
by = c("carrier" = "CARRIER")) # Ungleichnamige Schlüsselfelder angeben# A tibble: 336,776 × 7
time_hour flight origin dest carrier tailnum name
<dttm> <int> <chr> <chr> <chr> <chr> <chr>
1 2013-01-01 05:00:00 1545 EWR IAH UA N14228 United Air Lines Inc.
2 2013-01-01 05:00:00 1714 LGA IAH UA N24211 United Air Lines Inc.
3 2013-01-01 05:00:00 1141 JFK MIA AA N619AA American Airlines In…
4 2013-01-01 05:00:00 725 JFK BQN B6 N804JB JetBlue Airways
5 2013-01-01 06:00:00 461 LGA ATL DL N668DN Delta Air Lines Inc.
6 2013-01-01 05:00:00 1696 EWR ORD UA N39463 United Air Lines Inc.
7 2013-01-01 06:00:00 507 EWR FLL B6 N516JB JetBlue Airways
8 2013-01-01 06:00:00 5708 LGA IAD EV N829AS ExpressJet Airlines …
9 2013-01-01 06:00:00 79 JFK MCO B6 N593JB JetBlue Airways
10 2013-01-01 06:00:00 301 LGA ORD AA N3ALAA American Airlines In…
# ℹ 336,766 more rowsEin weiteres Beispiel festigt unser Verständnis. Zunächst erzeugen wir eine Auswahl an weather-Variablen.
weather2 <- weather |>
select(origin, time_hour, temp, wind_speed) # Vier Spalten auswählen
weather2# A tibble: 26,115 × 4
origin time_hour temp wind_speed
<chr> <dttm> <dbl> <dbl>
1 EWR 2013-01-01 01:00:00 39.0 10.4
2 EWR 2013-01-01 02:00:00 39.0 8.06
3 EWR 2013-01-01 03:00:00 39.0 11.5
4 EWR 2013-01-01 04:00:00 39.9 12.7
5 EWR 2013-01-01 05:00:00 39.0 12.7
6 EWR 2013-01-01 06:00:00 37.9 11.5
7 EWR 2013-01-01 07:00:00 39.0 15.0
8 EWR 2013-01-01 08:00:00 39.9 10.4
9 EWR 2013-01-01 09:00:00 39.9 15.0
10 EWR 2013-01-01 10:00:00 41 13.8
# ℹ 26,105 more rowsUm mehr über die Wetterlage unserer Flüge bei Abflug zu erfahren, möchten wir flights2 jetzt durch alle Variablen in weather2 ergänzen. Zuvor entfernen wir dest aus flights2, damit uns klar ist, dass sich die Informationen auf den Abflugsflughafen, also origin beziehen. Diesmal erfolgt der left join, wie uns R mitteilt, auf Basis eines zusammengesetzten Schlüssels aus origin und time_hour. Der neue data frame hat durch die Zusammenführung zwei neue Spalten, nämlich temp und windspeed, hinzugewonnen, während alle Zeilen aus flights2 erhalten bleiben
flights2 |>
select(- dest) |> # Spalte dest entfernen
left_join(weather2) # Left join durchführen# A tibble: 336,776 × 7
time_hour flight origin carrier tailnum temp wind_speed
<dttm> <int> <chr> <chr> <chr> <dbl> <dbl>
1 2013-01-01 05:00:00 1545 EWR UA N14228 39.0 12.7
2 2013-01-01 05:00:00 1714 LGA UA N24211 39.9 15.0
3 2013-01-01 05:00:00 1141 JFK AA N619AA 39.0 15.0
4 2013-01-01 05:00:00 725 JFK B6 N804JB 39.0 15.0
5 2013-01-01 06:00:00 461 LGA DL N668DN 39.9 16.1
6 2013-01-01 05:00:00 1696 EWR UA N39463 39.0 12.7
7 2013-01-01 06:00:00 507 EWR B6 N516JB 37.9 11.5
8 2013-01-01 06:00:00 5708 LGA EV N829AS 39.9 16.1
9 2013-01-01 06:00:00 79 JFK B6 N593JB 37.9 13.8
10 2013-01-01 06:00:00 301 LGA AA N3ALAA 39.9 16.1
# ℹ 336,766 more rows8.3.1.2 Right Join
Nachdem wir verstanden haben, wie ein left join funktioniert, ist die Erklärung eines right joins mittels right_join() für uns leichter zu verstehen: in diesem Fall handelt es sich nämlich lediglich um eine umgekehrte Ausgabetabelle. Das heißt, jede Zeile von y bleibt erhalten und wird lediglich um Variablen aus x ergänzt. Weil y die “rechte” Tabelle ist, handelt es sich um einen right join. Visuell sieht der Vorgang so aus:
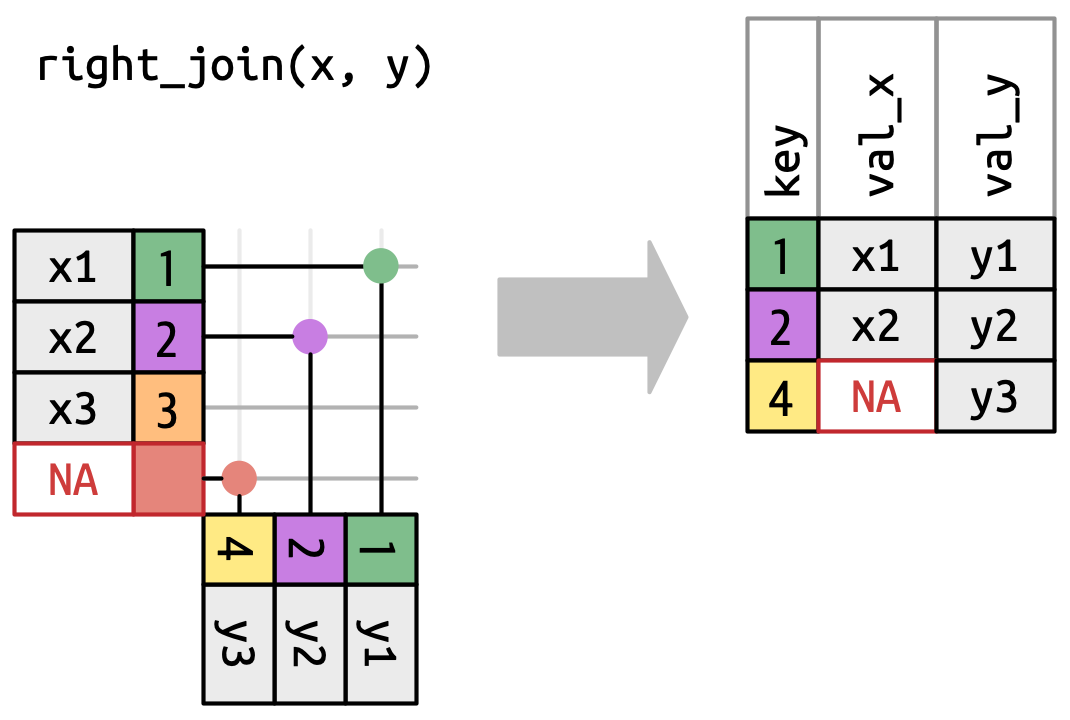
right_join() (Wickham, Çetinkaya-Rundel, und Grolemund 2023, Kap. 19.4).Um einen data frame mit denselben Informationen wie im vorherigen Beispiel von flights2 und weather2 zu erzeugen, würden wir also x und y einfach vertauschen. Das Ergebnis ist, bis auf die Reihenfolge der Spalten, gleich.
weather2 |>
right_join(flights2 |> # Right join durchführen
select(- dest)) # Variable dest aus flights2 entfernen# A tibble: 336,776 × 7
origin time_hour temp wind_speed flight carrier tailnum
<chr> <dttm> <dbl> <dbl> <int> <chr> <chr>
1 EWR 2013-01-01 05:00:00 39.0 12.7 1545 UA N14228
2 EWR 2013-01-01 05:00:00 39.0 12.7 1696 UA N39463
3 EWR 2013-01-01 06:00:00 37.9 11.5 507 B6 N516JB
4 EWR 2013-01-01 06:00:00 37.9 11.5 1124 UA N53441
5 EWR 2013-01-01 06:00:00 37.9 11.5 1187 UA N76515
6 EWR 2013-01-01 06:00:00 37.9 11.5 343 B6 N644JB
7 EWR 2013-01-01 06:00:00 37.9 11.5 1895 AA N633AA
8 EWR 2013-01-01 06:00:00 37.9 11.5 1077 UA N53442
9 EWR 2013-01-01 06:00:00 37.9 11.5 3768 MQ N9EAMQ
10 EWR 2013-01-01 06:00:00 37.9 11.5 575 DL N326NB
# ℹ 336,766 more rows8.3.1.3 Full Join
Wenn wir weder nur alle Beobachtungen von x noch nur alle Beobachtungen von y in unserer zusammengeführten Tabelle behalten möchten, sondern den vollen Umfang beider Tabellen erhalten möchten, nutzen wir einen full join. Visuell können wir uns einen full join so vorstellen:
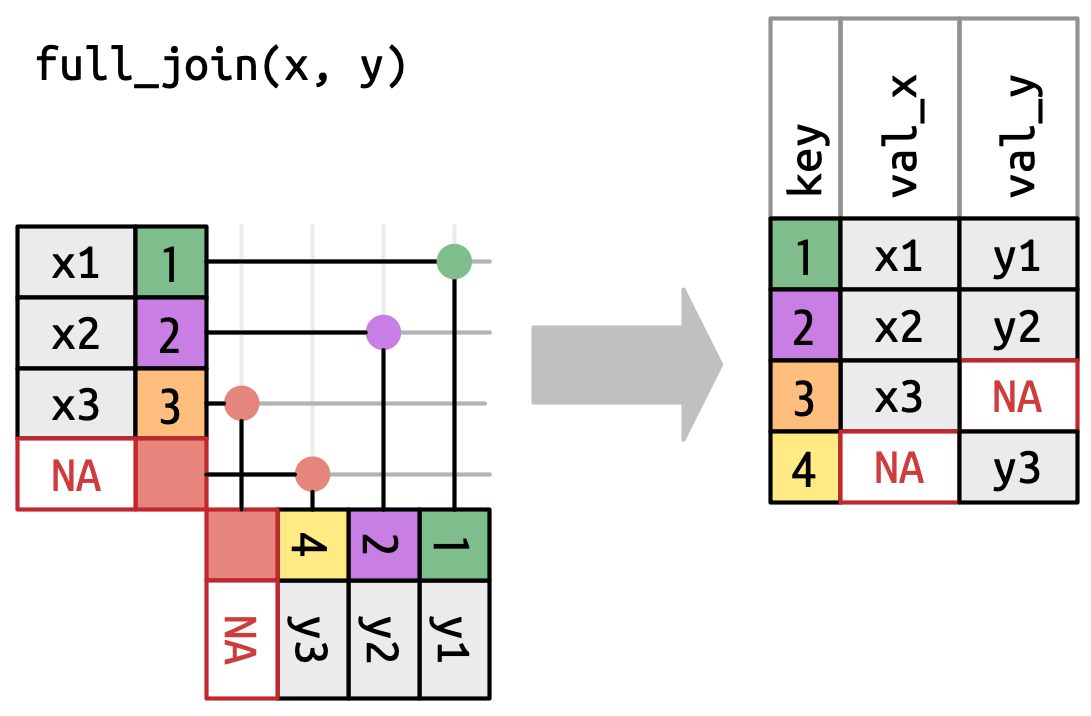
full_join() (Wickham, Çetinkaya-Rundel, und Grolemund 2023, Kap. 19.4).Wenn wir beispielsweise mittels slice_sample()4 zwei Stichproben von flights2 und weather2 mit je 1000 Beobachtungen erzeugen und full_join() zusammenfügen, hat die Ergebnistabelle nicht nur 1000 Beobachtungen (wie jeweils x und y haben), sondern mehr.5
set.seed(1234)
flights2_sample <- flights2 |>
slice_sample(n = 1000) # 1000 Fälle als Stichprobe ziehen
weather2_sample <- weather2 |>
slice_sample(n = 1000) # 1000 Fälle als Stichprobe ziehenflights2_weather2_full_join <- flights2_sample |>
full_join(weather2_sample) # Full join durchführen
flights2_weather2_full_join# A tibble: 1,968 × 8
time_hour flight origin dest carrier tailnum temp wind_speed
<dttm> <int> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 2013-06-17 10:00:00 244 EWR LAS UA N447UA NA NA
2 2013-12-26 13:00:00 2455 LGA MCO DL N373NW NA NA
3 2013-08-26 12:00:00 1623 EWR SNA UA N38727 NA NA
4 2013-08-17 16:00:00 543 EWR PBI B6 N558JB NA NA
5 2013-02-17 15:00:00 1753 EWR CLT US <NA> NA NA
6 2013-06-30 09:00:00 5 EWR FLL B6 N807JB NA NA
7 2013-09-15 10:00:00 1131 LGA DFW AA N3KMAA NA NA
8 2013-05-07 16:00:00 4411 EWR MEM EV N14558 NA NA
9 2013-03-14 06:00:00 1281 EWR CLT US N169UW NA NA
10 2013-09-04 07:00:00 11 JFK SFO VX N846VA 69.1 13.8
# ℹ 1,958 more rowsWas ist passiert? Ein full join hat alle Beobachtungen aus x und y behalten. In 33 Fällen gab es übereinstimmende Beobachtungen in beiden Tabellen, sodass diese nicht als neue Beobachtungen angehängt wurden. Deshalb ist die Gesamtanzahl der Beobachtungen nicht gleich 2000 (= 1000 aus x + 1000 aus y), sondern etwas weniger, nämlich 1968.
8.3.1.4 Inner Join
Das Gegenstück zu einem full join ist ein inner join: ein solcher join erzeugt eine Tabelle, die ausschließlich solche Beobachtungen enthält, die sowohl in x als auch in y enthalten sind.
flights2_weather2_inner_join <- flights2_sample |>
inner_join(weather2_sample) # Inner join durchführen
flights2_weather2_inner_join# A tibble: 33 × 8
time_hour flight origin dest carrier tailnum temp wind_speed
<dttm> <int> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 2013-09-04 07:00:00 11 JFK SFO VX N846VA 69.1 13.8
2 2013-06-17 10:00:00 1847 LGA ATL DL N915DE 81.0 5.75
3 2013-11-04 14:00:00 3231 JFK PIT MQ N638MQ 46.9 8.06
4 2013-09-04 07:00:00 23 JFK LAX B6 N806JB 69.1 13.8
5 2013-11-03 10:00:00 1529 JFK LAS DL N394DA 48.9 17.3
6 2013-04-13 16:00:00 4367 EWR GSO EV N15912 59 13.8
7 2013-04-05 16:00:00 4299 EWR DCA EV N13566 63.0 16.1
8 2013-07-31 11:00:00 3074 LGA DEN WN N946WN 79.0 3.45
9 2013-03-10 18:00:00 1973 EWR CLT US N536UW 39.0 9.21
10 2013-02-14 13:00:00 117 JFK LAX AA N335AA 44.1 12.7
# ℹ 23 more rows
Check, check!
Dass die vollständigen Beobachtungen eines full join gleich den Beobachtungen eines inner join sind, können wir in zwei Schritten überprüfen.
- Wir entfernen mit
drop_na()alle Beobachtungen ausflights2_weather2_full_join, die in irgendeiner Variable fehlende Werte (NAs) aufweisen. - Wir überprüfen mit
identical()6, ob dieflights2_weather2_full_joinohne fehlende Werte gleichflights2_weather2_inner_joinist.
identical(flights2_weather2_full_join |>
drop_na(),
flights2_weather2_inner_join)[1] TRUEAbschließend lassen sich die vier Formen von mutating joins und damit die Schnittmengen zwischen x und y auch in Form eines sog. Venn-Diagramms darstellen.
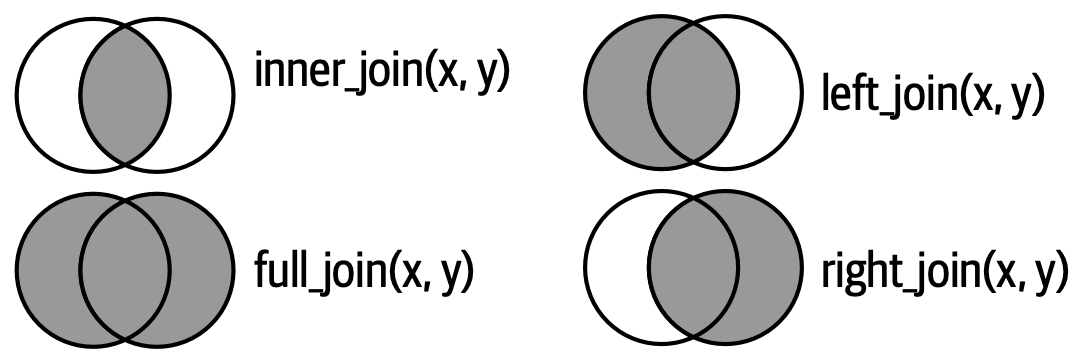
8.3.2 Filtering Joins
Während mutating joins Tabellen ergänzen, werden filtering joins genutzt, um Beobachtungen in x auf Basis von dem (Nicht-)Vorhandensein von Beobachtungen in y zu filtern. Es werden also keine Beobachtungen ergänzt oder wiederholt.
8.3.2.1 Semi Join
Ein semi join überprüft die Beobachtungen von x auf entsprechende Beobachtungen in y. Wird eine Übereinstimmung gefunden, wird die Beobachtung in die Ergebnistabelle übernommen; wird sie das nicht, wird die Beobachtung entfernt bzw. “fallengelassen” (drop). Visuell können wir uns einen semi join so vorstellen:
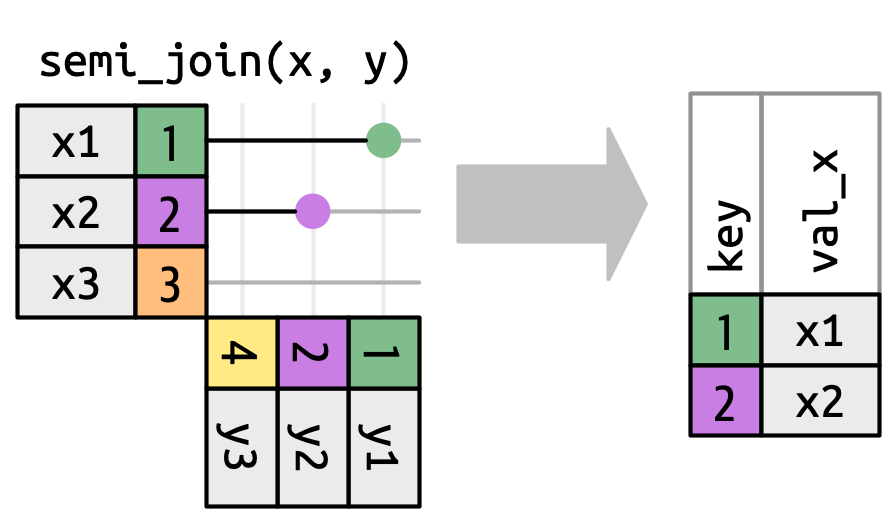
semi_join() (Wickham, Çetinkaya-Rundel, und Grolemund 2023, Kap. 19.4).Wir können uns dieses Vorgehen anhand von flights2_sample und weather2_sample gut verständlich machen. Möchten wir nur die Beobachtungen in flights2_sample ausgeben, für die in weather2_sample Wetterinformationen vorhanden sind, dabei aber keine Variablen in flights2_sample ergänzen, nutzen wir semi_join().
flights2_sample |>
semi_join(weather2_sample) # Semi join durchführen# A tibble: 33 × 6
time_hour flight origin dest carrier tailnum
<dttm> <int> <chr> <chr> <chr> <chr>
1 2013-09-04 07:00:00 11 JFK SFO VX N846VA
2 2013-06-17 10:00:00 1847 LGA ATL DL N915DE
3 2013-11-04 14:00:00 3231 JFK PIT MQ N638MQ
4 2013-09-04 07:00:00 23 JFK LAX B6 N806JB
5 2013-11-03 10:00:00 1529 JFK LAS DL N394DA
6 2013-04-13 16:00:00 4367 EWR GSO EV N15912
7 2013-04-05 16:00:00 4299 EWR DCA EV N13566
8 2013-07-31 11:00:00 3074 LGA DEN WN N946WN
9 2013-03-10 18:00:00 1973 EWR CLT US N536UW
10 2013-02-14 13:00:00 117 JFK LAX AA N335AA
# ℹ 23 more rowsUnsere Ergebnistabelle sieht dem Ergebnis eines inner join (Kapitel 8.3.1.4) sehr ähnlich, beinhaltet aber nur die Variablen aus flights2_sample.
8.3.2.2 Anti Join
Ein anti join stellt das Gegenstück zu einem semi join dar. In diesem Fall werden nur Beobachtungen in x in die Ergebnistabelle übernommen, für die keine Übereinstimmung in y vorliegt. Wie zuvor werden aber keine Variablen ergänzt. Visuell sieht dieser Vorgang so aus:
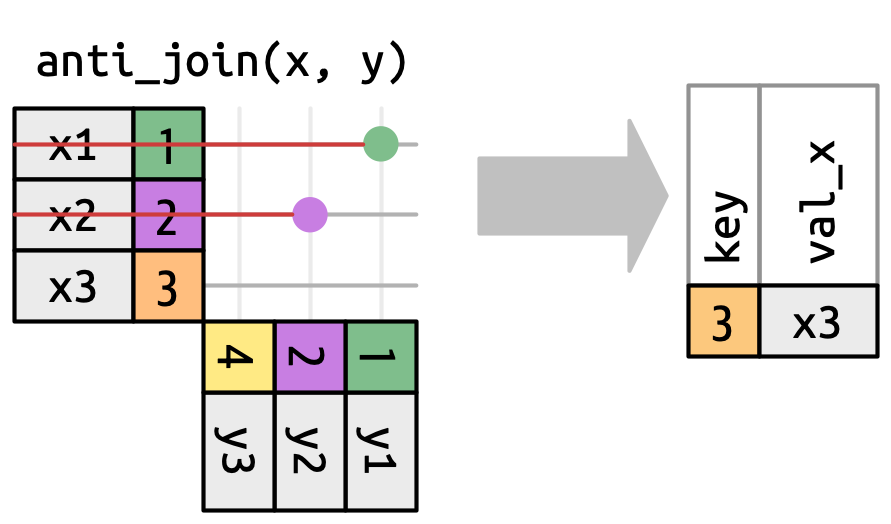
anti_join() (Wickham, Çetinkaya-Rundel, und Grolemund 2023, Kap. 19.4).Anhand von flights2_sample und weather2_sample werden also nur die Fälle in flights2_sample gefiltert, für die keine Wetterinformationen in weather2_sample vorliegen.
flights2_sample |>
anti_join(weather2_sample) # Anti join durchführen# A tibble: 967 × 6
time_hour flight origin dest carrier tailnum
<dttm> <int> <chr> <chr> <chr> <chr>
1 2013-06-17 10:00:00 244 EWR LAS UA N447UA
2 2013-12-26 13:00:00 2455 LGA MCO DL N373NW
3 2013-08-26 12:00:00 1623 EWR SNA UA N38727
4 2013-08-17 16:00:00 543 EWR PBI B6 N558JB
5 2013-02-17 15:00:00 1753 EWR CLT US <NA>
6 2013-06-30 09:00:00 5 EWR FLL B6 N807JB
7 2013-09-15 10:00:00 1131 LGA DFW AA N3KMAA
8 2013-05-07 16:00:00 4411 EWR MEM EV N14558
9 2013-03-14 06:00:00 1281 EWR CLT US N169UW
10 2013-07-31 08:00:00 15 JFK SFO B6 N536JB
# ℹ 957 more rows8.3.3 Weitere Arten von Join
Mit den in diesem Kapitel vorgestellten Arten von joins ist bereits ein großer Bereich abgedeckt. Für weitere Anwendungen finden sich bei Wickham, Çetinkaya-Rundel, und Grolemund (2023, Kap. 19.5) noch fortgeschrittene Funktionen.
8.4 Übungsaufgaben
A long time ago in a galaxy far, far away…

Die folgenden Übungsaufgaben beziehen sich auf neun data frames aus dem Package starwarsdb. Wenn wir starwarsdb bereits installiert haben, müssen wir es nur noch mit library(starwarsdb) laden. Wenn wir starwarsdb noch nicht installiert haben (was einige Minuten dauert), können wir stattdessen diese RDATA-Datei herunterladen und sie dann mit mit load() laden:
load("./files/starwars.rdata")Die folgenden neun data frames stehen uns dann zur Verfügung, deren Inhalte wir mit glimpse() betrachten können:
films: Detaillierte Angaben zu Filmen.films_people: Angaben zu Charakteren je nach Film.films_planet: Angaben zu Planeten je nach Film.films_vehicles: Angaben zu Vehikeln je nach Film.people: Detaillierte Angaben zu Charakteren.pilots: Angaben zu Piloten je nach Vehikel.planets: Detaillierte Angaben zu Planeten.species: Detallierte Angaben zu Spezien.vehicles: Detaillierte Angaben zu Vehikeln.
In den folgenden Aufgaben werden mindestens zwei data frames zusammengeführt. Hierfür müssen wir zunächst passende Schlüsselfelder (Primär- und Fremdschlüssel) identifizieren. Wichtig ist, dass diese Schlüssel nicht immer dieselbe Bezeichnung tragen – anders als in den Erläuterungen oben. Bei den meisten joins müssen wir also by nutzen.
8.4.1 Left Join
- Führen Sie
films_planetsundplanetszusammen. Die Ergebnistabelle soll so aussehen:
# A tibble: 33 × 10
title planet rotation_period orbital_period diameter climate gravity terrain
<chr> <chr> <dbl> <dbl> <dbl> <chr> <chr> <chr>
1 A New… Tatoo… 23 304 10465 arid 1 stan… desert
2 A New… Alder… 24 364 12500 temper… 1 stan… grassl…
3 A New… Yavin… 24 4818 10200 temper… 1 stan… jungle…
4 The E… Hoth 23 549 7200 frozen 1.1 st… tundra…
5 The E… Dagob… 23 341 8900 murky <NA> swamp,…
6 The E… Bespin 12 5110 118000 temper… 1.5 (s… gas gi…
7 The E… Ord M… 26 334 14050 temper… 1 stan… plains…
8 Retur… Tatoo… 23 304 10465 arid 1 stan… desert
9 Retur… Dagob… 23 341 8900 murky <NA> swamp,…
10 Retur… Endor 18 402 4900 temper… 0.85 s… forest…
# ℹ 23 more rows
# ℹ 2 more variables: surface_water <dbl>, population <dbl>- Werten Sie die Tabelle mittels
group_by()undcount()so aus, dass Sie erfahren, in welchem Film die meisten unterschiedlichen Planeten vorkamen. Die Ergebnistabelle soll so aussehen:
# A tibble: 6 × 2
# Groups: title [6]
title n
<chr> <int>
1 Revenge of the Sith 13
2 Attack of the Clones 5
3 Return of the Jedi 5
4 The Empire Strikes Back 4
5 A New Hope 3
6 The Phantom Menace 38.4.2 Right Join
- Führen Sie
peopleundfilms_peoplezusammen. Die Ergebnistabelle soll so aussehen:
# A tibble: 162 × 12
name height mass hair_color skin_color eye_color birth_year gender
<chr> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 Luke Skywalker 172 77 blond fair blue 19 mascu…
2 Luke Skywalker 172 77 blond fair blue 19 mascu…
3 Luke Skywalker 172 77 blond fair blue 19 mascu…
4 Luke Skywalker 172 77 blond fair blue 19 mascu…
5 C-3PO 167 75 <NA> gold yellow 112 mascu…
6 C-3PO 167 75 <NA> gold yellow 112 mascu…
7 C-3PO 167 75 <NA> gold yellow 112 mascu…
8 C-3PO 167 75 <NA> gold yellow 112 mascu…
9 C-3PO 167 75 <NA> gold yellow 112 mascu…
10 C-3PO 167 75 <NA> gold yellow 112 mascu…
# ℹ 152 more rows
# ℹ 4 more variables: homeworld <chr>, species <chr>, sex <chr>, title <chr>- Werten Sie die Tabelle mittels
filter(),group_by()undcount()so aus, dass Sie erfahren, in welchem Film die meisten Wookies (species == "Wookie") vorkamen. Die Ergebnistabelle soll so aussehen:
# A tibble: 4 × 2
# Groups: title [4]
title n
<chr> <int>
1 Revenge of the Sith 2
2 A New Hope 1
3 Return of the Jedi 1
4 The Empire Strikes Back 18.4.3 Full Join
- Führen Sie
films_vehiclesundvehicleszusammen. Die Ergebnistabelle soll so aussehen:
# A tibble: 104 × 15
title vehicle type class model manufacturer cost_in_credits length
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 A New Hope CR90 c… star… corv… CR90… Corellian E… 3500000 1.5 e2
2 A New Hope Star D… star… Star… Impe… Kuat Drive … 150000000 1.6 e3
3 A New Hope Sentin… star… land… Sent… Sienar Flee… 240000 3.8 e1
4 A New Hope Death … star… Deep… DS-1… Imperial De… 1000000000000 1.20e5
5 A New Hope Millen… star… Ligh… YT-1… Corellian E… 100000 3.44e1
6 A New Hope Y-wing star… assa… BTL … Koensayr Ma… 134999 1.4 e1
7 A New Hope X-wing star… Star… T-65… Incom Corpo… 149999 1.25e1
8 A New Hope TIE Ad… star… Star… Twin… Sienar Flee… NA 9.2 e0
9 The Empire Str… Star D… star… Star… Impe… Kuat Drive … 150000000 1.6 e3
10 The Empire Str… Millen… star… Ligh… YT-1… Corellian E… 100000 3.44e1
# ℹ 94 more rows
# ℹ 7 more variables: max_atmosphering_speed <dbl>, crew <chr>,
# passengers <dbl>, cargo_capacity <dbl>, consumables <chr>,
# hyperdrive_rating <dbl>, MGLT <dbl>- Werten Sie die Tabelle mittels
filter(),group_by()undsummarize()so aus, dass Sie erfahren, in welchem Film die schnellsten (mean(max_atmosphering_speed, na.rm = TRUE)) Raumschiffe (type == "starship") vorkamen. Die Ergebnistabelle soll so aussehen:
# A tibble: 6 × 2
title mean_speed
<chr> <dbl>
1 Attack of the Clones 2475
2 Revenge of the Sith 1182.
3 A New Hope 1032.
4 The Phantom Menace 1025
5 Return of the Jedi 958.
6 The Empire Strikes Back 922.8.4.4 Inner Join
- Führen Sie
vehiclesundpilotszusammen. Die Ergebnistabelle soll so aussehen:
# A tibble: 43 × 15
name type class model manufacturer cost_in_credits length
<chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 Millennium Falcon starship Light f… YT-1… Corellian E… 100000 34.4
2 Millennium Falcon starship Light f… YT-1… Corellian E… 100000 34.4
3 Millennium Falcon starship Light f… YT-1… Corellian E… 100000 34.4
4 Millennium Falcon starship Light f… YT-1… Corellian E… 100000 34.4
5 X-wing starship Starfig… T-65… Incom Corpo… 149999 12.5
6 X-wing starship Starfig… T-65… Incom Corpo… 149999 12.5
7 X-wing starship Starfig… T-65… Incom Corpo… 149999 12.5
8 X-wing starship Starfig… T-65… Incom Corpo… 149999 12.5
9 TIE Advanced x1 starship Starfig… Twin… Sienar Flee… NA 9.2
10 Slave 1 starship Patrol … Fire… Kuat System… NA 21.5
# ℹ 33 more rows
# ℹ 8 more variables: max_atmosphering_speed <dbl>, crew <chr>,
# passengers <dbl>, cargo_capacity <dbl>, consumables <chr>,
# hyperdrive_rating <dbl>, MGLT <dbl>, pilot <chr>- Werten Sie die Tabelle mittels
group_by()undcount()so aus, dass Sie erfahren, welche Vehikel die meisten unterschiedlichen Pilot*innen hatten. Die Ergebnistabelle soll so aussehen:
# A tibble: 25 × 2
# Groups: name [25]
name n
<chr> <int>
1 Millennium Falcon 4
2 X-wing 4
3 Imperial shuttle 3
4 Naboo fighter 3
5 Belbullab-22 starfighter 2
6 Imperial Speeder Bike 2
7 Jedi Interceptor 2
8 Jedi starfighter 2
9 Naboo star skiff 2
10 Snowspeeder 2
# ℹ 15 more rows8.4.5 Semi Join
- Fügen Sie zunächst
films_planetsund die Spaltentitleundepisode_idausfilmsmitleft_join()zusammen. Nutzen Sie dannfilter(), um nur die ersten drei Episoden auszuwählen (between(episode_id, 1, 3)). Die Ergebnistabelle sollplanet_names_first_trilogyheißen und so aussehen:
Joining with `by = join_by(title)`# A tibble: 21 × 3
title planet episode_id
<chr> <chr> <int>
1 The Phantom Menace Tatooine 1
2 The Phantom Menace Naboo 1
3 The Phantom Menace Coruscant 1
4 Attack of the Clones Tatooine 2
5 Attack of the Clones Naboo 2
6 Attack of the Clones Coruscant 2
7 Attack of the Clones Kamino 2
8 Attack of the Clones Geonosis 2
9 Revenge of the Sith Tatooine 3
10 Revenge of the Sith Alderaan 3
# ℹ 11 more rows- Führen Sie desweiteren
planetsundplanet_names_first_trilogymittelssemi_join()zusammen, um eine Ergebnistabelle zu erzeugen, die nur die Planeteninformationen der ersten drei Episoden enthält. Die Ergebnistabelle soll so aussehen:
# A tibble: 15 × 9
name rotation_period orbital_period diameter climate gravity terrain
<chr> <dbl> <dbl> <dbl> <chr> <chr> <chr>
1 Tatooine 23 304 10465 arid 1 stan… desert
2 Alderaan 24 364 12500 temper… 1 stan… grassl…
3 Dagobah 23 341 8900 murky <NA> swamp,…
4 Naboo 26 312 12120 temper… 1 stan… grassy…
5 Coruscant 24 368 12240 temper… 1 stan… citysc…
6 Kamino 27 463 19720 temper… 1 stan… ocean
7 Geonosis 30 256 11370 temper… 0.9 st… rock, …
8 Utapau 27 351 12900 temper… 1 stan… scrubl…
9 Mustafar 36 412 4200 hot 1 stan… volcan…
10 Kashyyyk 26 381 12765 tropic… 1 stan… jungle…
11 Polis Massa 24 590 0 artifi… 0.56 s… airles…
12 Mygeeto 12 167 10088 frigid 1 stan… glacie…
13 Felucia 34 231 9100 hot, h… 0.75 s… fungus…
14 Cato Neimoid… 25 278 0 temper… 1 stan… mounta…
15 Saleucami 26 392 14920 hot <NA> caves,…
# ℹ 2 more variables: surface_water <dbl>, population <dbl>8.4.6 Anti Join
Führen Sie planets und planet_names_first_trilogy zusammen, um eine Ergebnistabelle zu erzeugen, die nur die Planeteninformationen aller Planeten, die nicht in den ersten drei Episoden vorkommen, enthält. Die Ergebnistabelle soll so aussehen:
# A tibble: 44 × 9
name rotation_period orbital_period diameter climate gravity terrain
<chr> <dbl> <dbl> <dbl> <chr> <chr> <chr>
1 Yavin IV 24 4818 10200 temperate,… 1 stan… jungle…
2 Hoth 23 549 7200 frozen 1.1 st… tundra…
3 Bespin 12 5110 118000 temperate 1.5 (s… gas gi…
4 Endor 18 402 4900 temperate 0.85 s… forest…
5 Stewjon NA NA 0 temperate 1 stan… grass
6 Eriadu 24 360 13490 polluted 1 stan… citysc…
7 Corellia 25 329 11000 temperate 1 stan… plains…
8 Rodia 29 305 7549 hot 1 stan… jungle…
9 Nal Hutta 87 413 12150 temperate 1 stan… urban,…
10 Dantooine 25 378 9830 temperate 1 stan… oceans…
# ℹ 34 more rows
# ℹ 2 more variables: surface_water <dbl>, population <dbl>8.5 Lösungen
8.5.1 Left Join
films_planets |>
left_join(planets,
by = c("planet" = "name"))films_planets |>
left_join(planets,
by = c("planet" = "name")) |>
group_by(title) |>
count(sort = TRUE)8.5.2 Right Join
people |>
right_join(films_people,
by = c("name" = "character"))people |>
right_join(films_people,
by = c("name" = "character")) |>
filter(species == "Wookie") |>
group_by(title) |>
count(sort = TRUE)8.5.3 Full Join
films_vehicles |>
full_join(vehicles,
by = c("vehicle" = "name"))films_vehicles |>
full_join(vehicles,
by = c("vehicle" = "name")) |>
filter(type == "starship") |>
group_by(title) |>
summarize(mean_speed = mean(max_atmosphering_speed, na.rm = TRUE)) |>
arrange(desc(mean_speed))8.5.4 Inner Join
vehicles |>
inner_join(pilots,
by = c("name" = "vehicle"))vehicles |>
inner_join(pilots,
by = c("name" = "vehicle")) |>
group_by(name) |>
count(sort = TRUE)8.5.5 Semi Join
planet_names_first_trilogy <- films_planets |>
left_join(films |>
select(title, episode_id)) |>
filter(between(episode_id, 1, 3))
planet_names_first_trilogyplanets |>
semi_join(planet_names_first_trilogy,
by = c("name" = "planet"))8.5.6 Anti Join
planets |>
anti_join(planet_names_first_trilogy,
by = c("name" = "planet"))Dieses Kapitel basiert auf Wickham, Çetinkaya-Rundel, und Grolemund (2023, Kap. 19).↩︎
Das
tidyversehat joins keineswegs erfunden. Left joins, right joins, inner joins und full joins sind auch im Rahmen von base R unter Nutzung der Funktionmerge()möglich (siehe?merge).↩︎Bei einem Schlüsselfeld genügt die Nennung als
character. Bei zwei oder mehr Schlüsselfelder müssen diese mitc()angegeben werden.↩︎Hierbei handelt es sich um eine weitere Spielart der uns bereits bekannte
slice_*()-Funktionen (Kapitel 4.2.2).↩︎Der Funktionsaufruf
set.seed(1234)wird benötigt, um die Zufallsstichprobe nachvollziehbar zu machen, sodass der folgendeslice_sample()-Aufruf auf jedem Computer dieselbe Stichprobe generiert. Eine Erläutering findet sich in diesem Blogbeitrag.↩︎identical()gibtTRUEaus, wenn zwei Objekte einander gleichen undFALSE, wenn dies nicht der Fall ist.↩︎